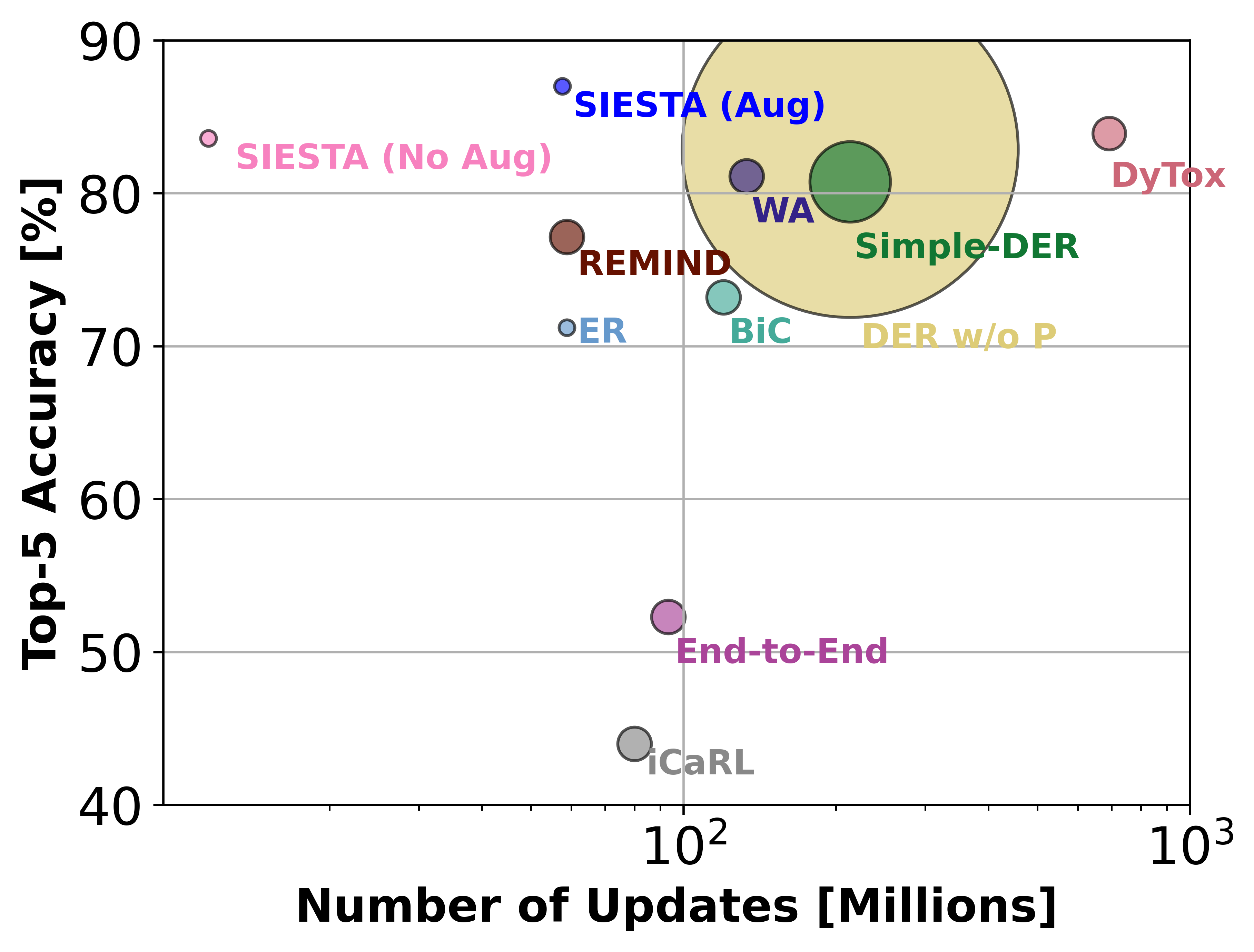
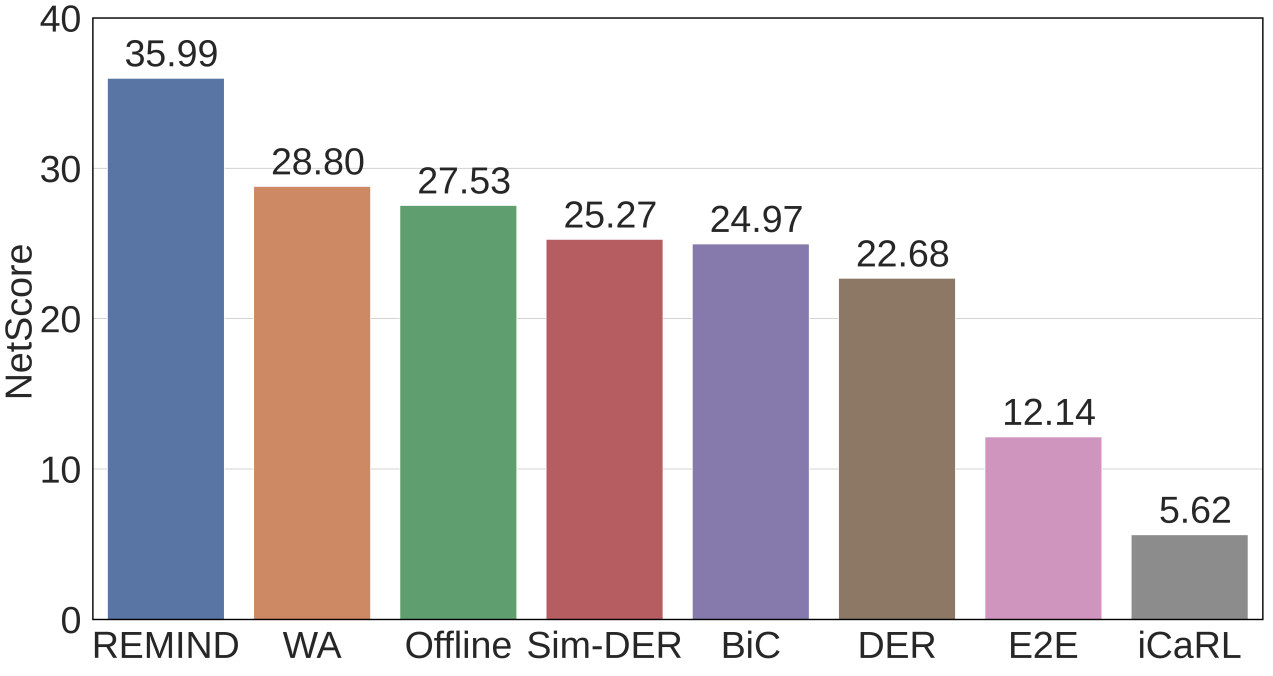
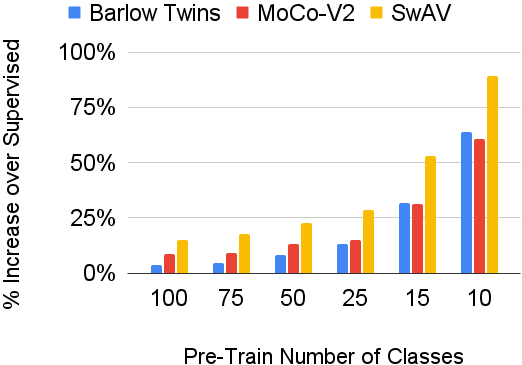
About Me
Hello! I am a PhD Candidate working under the supervision of Dr. Christopher Kanan in Chester F. Carlson Center for Imaging Science at Rochester Institute of Technology (RIT). My current research focuses on self-supervised learning and continual learning. I am mainly interested in efficient continual representation learning systems with minimal supervision. Previously, I interned at Siemens Healthineers, where I worked on self-supervised learning techniques for medical imaging.
I received an BS in Mechatronics Engineering from Universidad Nacional de Ingeniería where I worked on deep learning techniques for diabetic retinopathy detection and Simultaneous Localization and Mapping (SLAM) techniques for mobile robot exploration.
You can find my CV here.
Here is my Google Scholar.